CAA2026 – Turning Legacy Archaeological Images into Reusable Data
At CAA2026, I will be presenting a small but very practical piece of work: a reproducible workflow to turn a legacy archaeological image collection into a structured, machine-learning-ready dataset.
This talk is part of the Little Minions session, which focuses on those small tools we build in the background to actually get research done.
The problem: access vs usability
Archaeology has no shortage of digital data.
Repositories such as the Archaeology Data Service (ADS) have made large datasets publicly accessible, including image collections, metadata, and documentation. However, in many cases, access does not equal usability.
A good example is the dataset Lower Palaeolithic technology, raw material and population ecology by Marshall, Dupplaw, Roe and Gamble, 2002, hosted at the ADS which contains:
- 10,668 images
- 3,556 artefacts
- Rich metadata (raw material, measurements, provenance)
All of this is available online… but:
- no bulk download
- no API
- manual navigation required for each record
This creates a bottleneck. The data exists, but using it at scale becomes slow, repetitive, and difficult to reproduce.

A small tool approach
Instead of building a complex system, the goal is deliberately simple:
Can we turn this dataset into something usable with a lightweight, reproducible workflow?
The solution consists of two small, open tools:
- A web scraping script
- An image processing pipeline
Both are intentionally minimal, transparent, and easy to reuse.
This is very much in the spirit of “little minions”: small helpers that quietly improve research workflows without being the main focus of publications.
Step 1: scraping the dataset
The first step is automating what a researcher would otherwise do manually:
- visit each record page
- extract metadata
- download images
A short Python script handles this by:
- iterating through record IDs
- parsing HTML pages
- saving metadata into a CSV
- downloading associated images
Some important considerations:
- respecting
robots.txt - adding delays between requests
- checking ADS Terms of Use
The result:
- a complete local copy of the dataset (images + metadata)
- a structured CSV ready for analysis
What would normally require hours of manual work becomes reproducible in a single run.
Step 2: structuring and segmenting images
Once the data is local, the second step prepares it for computational analysis.
The pipeline performs three main tasks:
1. Standardising filenames
Images are renamed using UUIDs to avoid collisions when merging datasets.
2. Creating a COCO dataset
A JSON file is generated following the COCO format:
- image metadata
- bounding boxes
- segmentation masks
- collection-level information
This provides a standard structure widely used in computer vision.
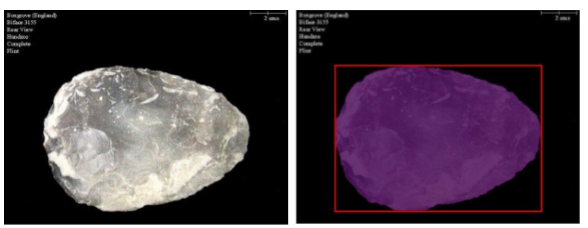
3. Segmenting artefacts
Using classical computer vision:
- detect contours
- select the largest contour (the artefact)
- generate:
- binary masks
- bounding boxes
This works well because the dataset follows a controlled format:
- one object per image
- dark background
- labels separated from the artefact
The result is a segmentation-ready dataset, without manual annotation.
Why not deep learning?
One of the key decisions in this work is to avoid deep learning for segmentation.
Instead, the workflow uses:
- thresholding
- contour detection
This comes with trade-offs:
Pros
- transparent
- lightweight
- easy to reproduce
- no training data required
Cons
- sensitive to lighting and contrast
- less robust in complex images
For this specific dataset, the controlled photographic setup makes classical methods a very reasonable choice.
Outputs and reuse
The workflow produces:
- CSV with full metadata
- local image collection
- UUID mapping table
- COCO annotation file
- segmentation masks and bounding boxes
Crucially:
The original images are not redistributed. Only derived data is shared.
This respects repository licensing while still enabling open workflows.
What this enables
Once the dataset is structured, a lot becomes possible:
- morphometric analysis
- computer vision experiments
- cross-dataset comparisons
- integration with other collections
More importantly, the process becomes:
- reproducible
- transparent
- reusable
Limitations (and why they matter)
This is not a universal solution.
The workflow depends on:
- a stable website structure
- a specific image format
- one object per image
- controlled backgrounds
Adapting it to other datasets may require:
- new scraping logic
- different segmentation strategies
- possibly manual annotation or ML models
So this should be seen as a particular helping tool, not a final solution
A broader point
One of the key takeaways from this work is quite simple:
You do not always need complex systems to improve research workflows.
Sometimes:
- a short script
- a clear data structure
- and a focus on reproducibility
are enough to unlock the value of an existing dataset.
Preprint and code
If you want the full technical details, you can read the preprint here.
The scripts are available on GitHub here and here.
Final thoughts
This project is intentionally modest.
It focuses on one dataset, one workflow, and one specific use case. But it shows something important:
- legacy datasets are not “closed”
- small tools can unlock them
- reproducibility does not require complexity
And maybe most importantly:
many of these “little minions” already exist in our daily work, we just do not share them enough.
If you are attending CAA2026 and interested in this topic, feel free to come say hi before or after the talk (during the talk might be a bit distracting).